Mục lục
HashMap là một dạng CTDL lưu trữ các phần tử dưới dạng cặp key-value. Trong một HashMap instance luôn đảm bảo chỉ mỗi phần tử có key là duy nhất, ngoài ra HashMap còn cung cấp khả năng truy xuất phần tử nhanh chóng chỉ tốn 0(1) gần như là truy xuất trực tiếp.
Trong bài viết này chúng ta sẽ cùng tìm hiểu bên trong HashMap hoạt động như để đạt được những tính chất được kể trên.
Cấu trúc
Bên trong HashMap chứa một mảng các bucket, mỗi bucket sẽ chứa 1 hoặc nhiều Node tương ứng với từng phần tử mà chúng ta thêm vào HashMap. Mỗi Node sẽ chứa các đối tượng chính sau:
- int hash
- K key
- V value
- Node next
Hashing
Hashing là quá trình chuyển đổi một object sang một số nguyên bằng cách sử dụng hashCode() method. Triển khai hashCode() đúng cách sẽ giúp HashMap hoạt động hiệu quả hơn. Nhưng các bạn hãy yên tâm rằng các IDE hiện nay đều hỗ trợ sinh hashCode() một cách tự động, chúng ta không cần phải quan tâm đến vấn đề này nhiều như trước.
Dưới đây là class Key được triển khai hashCode() và equals() một cách đơn giản. Xin lưu ý rằng hashCode() trong class này sẽ không được áp dụng trong thực tế.
class Key
{
String key;
Key(String key)
{
this.key = key;
}
@Override
public int hashCode()
{
return (int)key.charAt(0);
}
@Override
public boolean equals(Object obj)
{
return key.equals((String)obj);
}
}
Method hashCode() được override đơn giản trả về mã ASCII của ký tự đầu tiên của string key.
Chúng ta cần nhớ một chút về equals() và hashCode() method:
- Các lần gọi hashCode() method phải trả về giá trị giống nhau trên cùng một object trong quá trình thực thi chương trình. Giá trị này không nhất thiết phải giống nhau giữa các lần chạy chương trình.
- Nếu 2 object bằng nhau khi so sánh thông qua equals() method thì chúng cũng phải có giá trị hashCode() bằng nhau.
- Không bắt buộc 2 object không bằng nhau phải có giá trị hashCode() khác nhau. Tuy nhiên nếu chúng có giá trị hashCode() khác nhau sẽ tăng hiệu xuất cho các bảng băm.
HashMap sử dụng hashCode() method trên Key class để tính toán giá trị của bucket nơi mà cặp giá trị key-value sẽ được lưu. Equals() được sử dụng để kiểm tra 2 object key có bằng nhau hay không nhầm xác định xem một object key đã tồn tại trong HashMap trước đó hay chưa.
Bucket
Được nhắc đến ở phần trước, HashMap dùng một mảng để lưu trữ bucket, mỗi bucket có thể có một hoặc nhiều Node.
Trong trường hợp có nhiều hơn một Node có cùng giá trị key hash thì bucket sẽ được tổ chức thành LinkedList liên kết các Node này.
Cách tính Index
Giá trị hash của key có thể tạo ra một giá trị rất lớn nằm trong vùng giới hạn của số nguyên cho nên nếu chúng ta sử dụng đúng giá trị hash này để trỏ đến index của phần tử trong mảng thì có thể chúng ta sẽ phải tạo ra một mảng có kích thước rất lớn, điều này là không cần thiết và còn có thể gây ra một số lỗi nguyên trọng như outOfMemoryException.
Vì vậy chúng ta cần cần ra một giải pháp để tính toán giá trị index dựa trên giá trị hash được trả về từ hashCode() method từ đó tối ưu kích thước của mảng cần tạo.
Giá trị index có thể tính dựa trên công thức đơn giản như sau:
index = hashCode(key) & (n-1).
Trong đó N là số lượng bucket mặc định cũng chính là kích thước mặc định của mảng trong HashMap.
Mô phỏng cách thêm phần tử trong HashMap
Giả sử chúng ta khởi tạo một HashMap rỗng thì kích thước mặc định của nó là 16 tương ứng với mảng Node bên trong nó cũng là 16.
Khi chúng ta thêm một phần tử mới vào mảng thông qua put() method
map.put(new Key("vishal"), 20);
Thì HashMap sẽ thực hiện các bước sau:
- Tính toán giá trị hash của Key {“vishal”} = 118.
- Tính toán giá trị index bằng method index() = 6.
- Khởi tạo một Node object và lưu vào mảng tạo vị trí index = 6.
{
int hash = 118
Key key = {"vishal"}
Integer value = 20
Node next = null
}
Tiếp theo, chúng ta lại thêm phần tử
map.put(new Key("sachin"), 30);
Thì HashMap lại thực hiện các bước sau:
- Tính toán giá trị hash của Key {“sachin”} = 115.
- Tính toán giá trị index bằng method index() = 3.
- Khởi tạo một Node object và lưu vào mảng tạo vị trí index = 3.
{
int hash = 115
Key key = {"sachin"}
Integer value = 30
Node next = null
}
Và khi chúng ta thêm một phần tử mới có cùng giá trị key hash với các phần tử trước đó.
map.put(new Key("vaibhav"), 40);
HashMap lại thực hiện các bước sau:
- Tính toán giá trị hash của Key {“vaibhav”} = 118.
- Tính toán giá trị index bằng method index() = 6.
{
int hash = 118
Key key = {"vaibhav"}
Integer value = 40
Node next = null
}
HashMap sẽ tiến hành lưu Obj này tại vị trí số 6 nếu chưa có phần tử nào được lưu tại đây. Tuy nhiên trong trường hợp này đã có một phần tử có Key {“vishal”} được lưu trước đó.
Trong trường hợp này HashMap sẽ duyệt tất cả các phần tử đang được lưu tại vị trí số 6 trong mảng, và sử dụng equals() method trên key object để kiểm tra:
- Nếu equals() trả về TRUE nghĩa là đã tồn tại phần tử có key trùng trước đó, HashMap sẽ tiến hành thay thế value hiện tại thành value mới vừa được thêm vào.
- Nếu duyệt hết các phần tử mà vẫn không có phần tử nào trùng key thì nó sẽ được liên kết các node trước đó tại vị trí số 6.
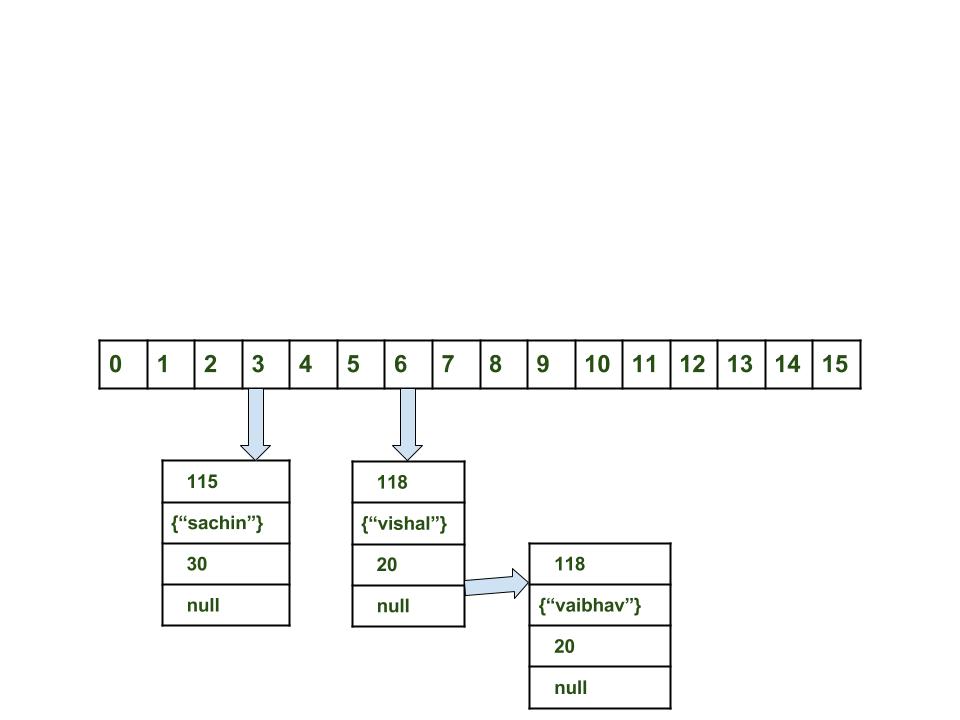
Mô phỏng cách truy xuất phần tử trong HashMap
Để truy xuất phần tử trong HashMap chúng ta sẽ phải sử dụng get(Key key) method.
map.get(new Key("sachin"));
Các bước thực hiện đằng sau get(Key key) method:
- Tính toán giá trị key hash = 115.
- Tính toán vị trí index = 3;
- Tiến đến vị trí index = 3 trong mảng tìm ra phần tử tương ứng (Mỗi phần tử trong mảng là một linkedlist chứa các phần tử có mã hey hash trùng nhau) bằng cách duyệt tất cả các phần tử và sử dụng equals() để kiểm tra và trả về value tương ứng khi equals() trả về TRUE.
- Trong trường hợp của chúng ta thì phần tử đầu tiên sẽ được tìm thấy và trả về giá trị 30.
Ví dụ tiếp theo chúng ta sẽ tìm kiếm phần tử với giá trị key là vaibhav.
map.get(new Key("vaibhav"));
Các bước được thực hiện:
- Tính toán giá trị key hash = 118.
- Tính vị trí index trong mảng = 6.
- Tiến đến vị trí index = 6 trong mảng tìm ra phần tử tương ứng bằng cách duyệt tất cả các phần tử và sử dụng equals() để kiểm tra và trả về value tương ứng khi equals() trả về TRUE.
- Trong trường hợp của chúng ta phần tử đầu tiên equals() sẽ trả về FALSE. Nếu con trỏ next bên trong phần tử này trỏ về NULL thì giá trị chúng ta nhận được sẽ là NULL.
- Ở đây phần tử tiếp của chúng ta cũng chính là phần tử chúng ta cần tìm, hàm Equals() sẽ trả về TRUE khi so sánh key với nhau.
Tóm lược
Từ những tính chất trên của HashMap chúng ta có thể thấy rằng trong trường hợp xấu nhất, rất nhiều tử có cùng giá trị hash của key thì chúng sẽ được lưu trên cùng bucket và liên kết với nhau thông qua linkedlist. Việc này sẽ ảnh hưởng rất xấu đến hiệu xuất tìm kiếm trên HashMap nếu chẳng may trường hợp này xảy ra.
Tuy nhiên các thuật toán hash ngày nay được nghiên cứu và phát triển rất nhiều nên phần nào chúng ta có thể yên tâm và vấn đề này.
Đây cũng là một câu hỏi mà mình khá tiếc khi bản thân đã đọc qua nhiều cuốn sách về Java và nghỉ mình đã nắm rõ kiến thức này. Tuy nhiên lâu không xem lại mình gần như quên đi 50% kiến thức và đó cũng là lý do lớn mà mình bị đánh failed khi phỏng vấn một công ty lớn trong TPHCM này. Khá tiếc nhưng thôi xem như nó là một bài học và cũng là động lực để mình viết bài này.
Nguồn
https://www.geeksforgeeks.org/internal-working-of-hashmap-java/
Cách hashCode method hoạt động trong Java